As engineers, we often tend to rely on what we know works without taking the time to evaluate if it is the best solution for the task at hand. One of the most common examples of this is the overuse of the reduce function in JavaScript. While reduce can be a powerful tool in many cases, it's important to consider the memory usage of reduce, especially when dealing with large data sets.
function createArray(count: number): number[] {
return new Array(count).fill(0).map((_, i) => i);
}
const small = createArray(10);
const medium = createArray(100);
const large = createArray(1000);
const huge = createArray(10000);
const whatYoureProbablyWorkingWith = createArray(1000000);
To demonstrate this, we can run a performance test on two functions - reduce and for loop - using five different input sizes: small, medium, large, huge, and an even larger one. But before we jump into the results, it's important to note that we warmed up the JIT (Just-In-Time) compiler before measuring the performance. This is to ensure that the performance measurements are as accurate as possible. More about JIT.
function forLoop(arr: number[]): number {
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i];
}
return sum;
}
function reduce(arr: number[]): number {
return arr.reduce((acc, x) => acc + x, 0);
}
function time(count: number, arr: number[], fn: (arr: number[]) => number): number {
const start = performance.now();
for (let i = 0; i < count; i++) {
fn(arr);
}
return performance.now() - start;
}
// warm up JIT
time(100, small, reduce);
time(100, small, forLoop);
We use the run array to specify how many times each function should be executed, and the numbers inside the arrays represent the time it took for each run in milliseconds. For example, in the "huge" input size, the for loop function was executed 4 times, with the execution times being 0.34830399975180626, 0.05027099885046482, 0.7388389987008406, and 7.367970000952482. (in ms)
const runs = [1, 10, 100, 1000];
let results = {
small: { reduce: [] as number[], forLoop: [] as number[] },
medium: { reduce: [] as number[], forLoop: [] as number[] },
large: { reduce: [] as number[], forLoop: [] as number[] },
huge: { reduce: [] as number[], forLoop: [] as number[] },
whatYoureProbablyWorkingWith: { reduce: [] as number[], forLoop: [] as number[] },
};
for (let i = 0; i < runs.length; i++) {
console.log("Starting", runs[i]);
const run = runs[i];
results.small.reduce.push(time(run, small, reduce));
results.small.forLoop.push(time(run, small, forLoop));
results.medium.reduce.push(time(run, medium, reduce));
results.medium.forLoop.push(time(run, medium, forLoop));
results.large.reduce.push(time(run, large, reduce));
results.large.forLoop.push(time(run, large, forLoop));
results.huge.reduce.push(time(run, huge, reduce));
results.huge.forLoop.push(time(run, huge, forLoop));
results.whatYoureProbablyWorkingWith.reduce.push(time(run, whatYoureProbablyWorkingWith, reduce));
results.whatYoureProbablyWorkingWith.forLoop.push(time(run, whatYoureProbablyWorkingWith, forLoop));
}
As you can see in the array below, the larger the input, the more efficient the for loop becomes. This is because the reduce function consumes a lot more memory than the for loop, making it less efficient for larger data sets.
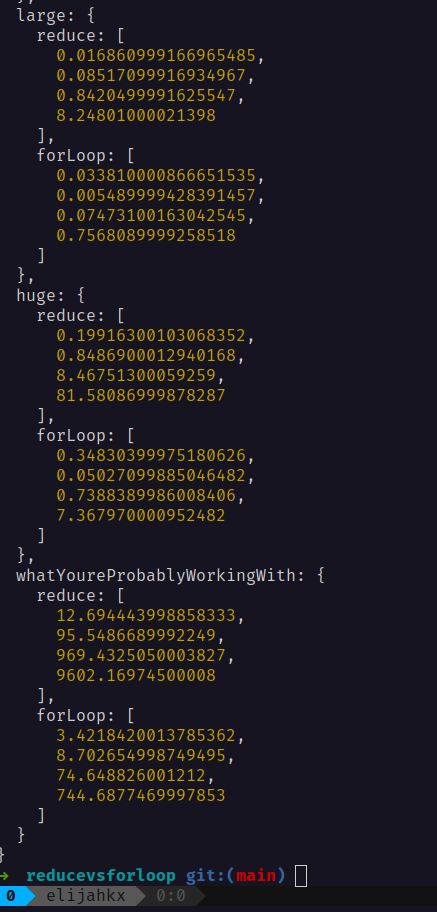
This doesn't mean reduce should never be used. In fact, there are many cases where reduce is the most efficient option. However, it's crucial to consider the memory usage and carefully evaluate which function is the best fit for the specific task at hand.
Therefore, it's important to consider the memory usage of different functions and evaluate which one is the best fit for the task you're dealing with.
Disclaimer: The code snippet I'm sharing with you is not my original work. I came across this information and found it to be valuable, so I wanted to pass it along. It's always important to give credit! (ThePrimeagen)
Check out the repo here.