Hey there! It's been some time :)
HashMaps are a fundamental data structure in programming, widely used for efficient data retrieval and storage. Chances are, you've utilized them in your code without much thought about their inner workings. Today, let's find out what's really happening behind HashMaps and understand the usage of hash functions, hash collisions, and how we handle them using linked lists.
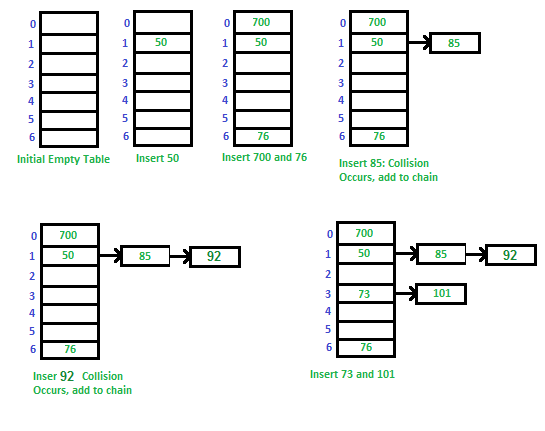 Image has been taken from GeeksOfGeeks
Image has been taken from GeeksOfGeeks
Why Hash Functions?
Imagine you need to find the room number of your favorite book in a massive library. Wandering around aimlessly would be tiresome and time-consuming. Instead, you'd use a book's title to find its unique identifier – the room number – in the library's index. That's precisely what hash functions do. They take any input (in our case, keys) and convert it into a unique number, the hash code, which acts as a quick index to locate the corresponding value in the HashMap.
How Hash Functions Work
In our example, we use the modulo operator to create a hash function. When a key is passed to the hash method, it calculates the hash code by taking the absolute value of the key's hash code and then performing a modulo operation with the size of the HashMap's underlying array. The result is an index where the key-value pair will be stored.
public class HashMap<K, V> {
private static final int DEFAULT_CAPACITY = 16;
private static final double LOAD_FACTOR_THRESHOLD = 0.75;
private Entry<K, V>[] table;
private int size;
public HashMap() {
table = new Entry[DEFAULT_CAPACITY];
size = 0;
}
private static class Entry<K, V> {
final K key;
V value;
Entry<K, V> next;
Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
private int hash(K key) {
return Math.abs(key.hashCode() % table.length);
}
Hash Collisions: The Bumps in the Road
But, there's a catch. Different keys can sometimes generate the same hash code, leading to what we call a "hash collision." It's like two books having the same room number in our library. Now we need a clever way to handle this situation.
Solving Hash Collisions with Linked Lists
Our HashMap takes hash collisions in stride. When two keys end up with the same hash code, instead of squeezing both values into one index, we create a linked list (or a bucket) at that index. Each element in the linked list contains a key-value pair. This way, we can smoothly manage multiple elements at the same hash code index.
public void put(K key, V value) {
if (key == null) {
throw new IllegalArgumentException("Null keys are not allowed.");
}
// We will talk about this a bit later
if ((double) size / table.length >= LOAD_FACTOR_THRESHOLD) {
resizeAndRehash();
}
int index = hash(key);
Entry<K, V> newEntry = new Entry<>(key, value);
if (table[index] == null) {
table[index] = newEntry;
} else {
Entry<K, V> current = table[index];
while (current.next != null) {
if (current.key.equals(key)) {
current.value = value;
return;
}
current = current.next;
}
current.next = newEntry;
}
size++;
}
Resizing and Rehashing
You may noticed a variable called LOAD_FACTOR_THRESHOLD, what's that you're wondering?
As our HashMap grows and more elements are added, we need to anticipate future collisions and ensure we have enough room to accommodate them. That's where "resizing and rehashing" come into play.
Picture this: you have a cozy home with limited shelf space for your books. As your book collection grows, you realize that you need more shelves. In the same way, our HashMap's underlying array has a fixed capacity. When the number of elements stored in the map becomes significant, it can lead to more frequent hash collisions, resulting in performance degradation.
To prevent our HashMap from becoming overcrowded, we proactively "resize" it when the load factor exceeds the LOAD_FACTOR_THRESHOLD. Resizing means doubling the capacity of the underlying array, to hold more key-value pairs.
private void resizeAndRehash() {
int newCapacity = table.length * 2;
Entry<K, V>[] newTable = new Entry[newCapacity];
for (Entry<K, V> entry : table) {
while (entry != null) {
Entry<K, V> next = entry.next;
int newIndex = Math.abs(entry.key.hashCode() % newCapacity);
entry.next = newTable[newIndex];
newTable[newIndex] = entry;
entry = next;
}
}
table = newTable;
}
How it works
- We double the capacity by multiplying the current capacity by 2 and create a new array newTable of that size.
- For each element in the current array, we rehash it and calculate a new index in the newTable.
- We insert the rehashed elements into the new array, distributing them to new positions based on their updated hash codes.
LOAD_FACTOR_THRESHOLD
The LOAD_FACTOR_THRESHOLD is usually set to a value between 0.5 and 0.75. If the load factor exceeds this threshold, the HashMap is resized and rehashed, which means the capacity of the array is increased to accommodate more elements, and all existing elements are rehashed and redistributed to new positions in the larger array.
By increasing the capacity and rehashing the elements, the HashMap ensures that the number of collisions remains low, which improves the performance of the put, get, and other operations. Having a lower load factor (e.g., 0.5) means the HashMap will resize more frequently but have less chance of collisions, while a higher load factor (e.g., 0.75) means the HashMap will resize less frequently but might have a higher chance of collisions.
In conlusion
So, the next time you encounter a HashMap, you'll appreciate the magic of its inner workings – from converting keys into hash codes to using linked lists to handle collisions and dynamically resizing when needed, while at the same time ensuring you have excellent performance.
Here's the full code to play around: repo