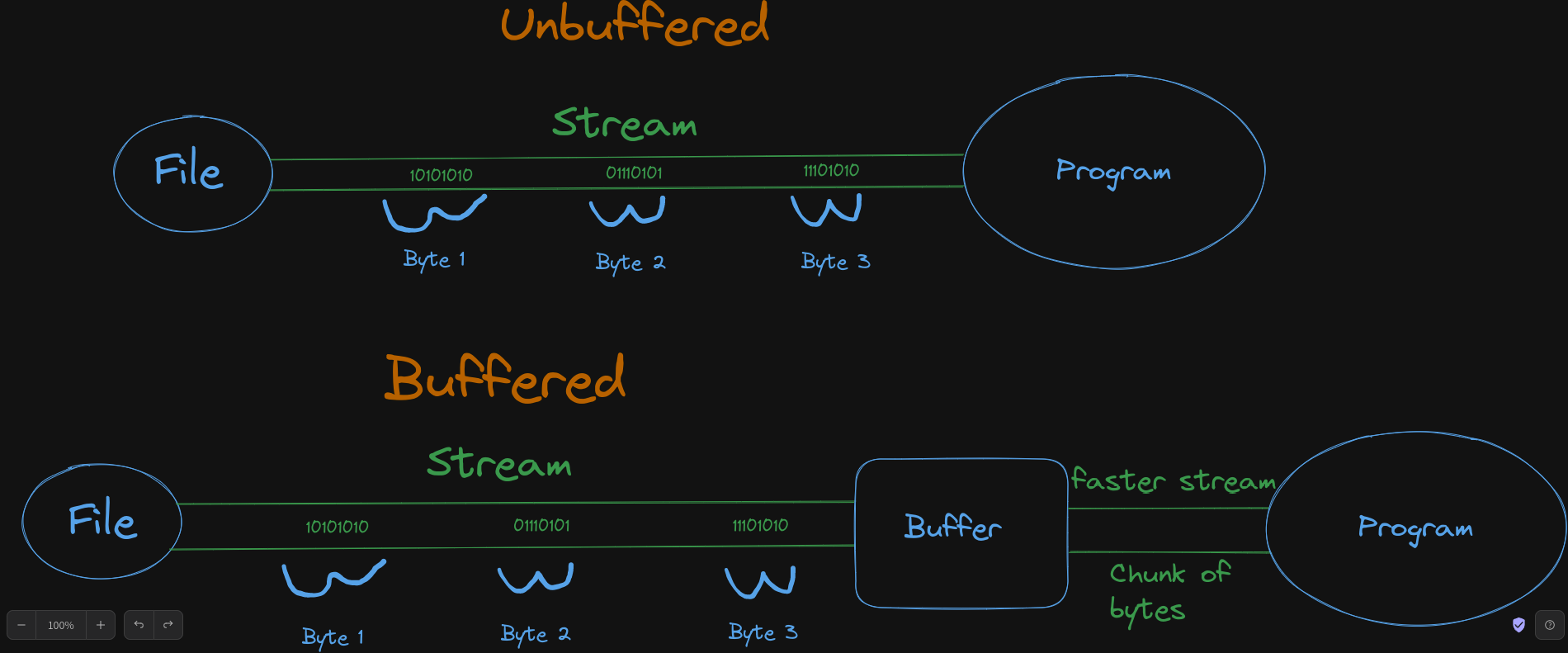
While I was studying the input/output operations in Java, I noticed that there's a huge difference between using a Buffered vs an Unbuffered Streams. The choice of stream implementation can have a significant impact on performance!
Understanding Bytes and Integers
In Java, bytes are treated as signed integers in the range of -128 to 127. However, when working with file I/O, we typically consider bytes as unsigned integers in the range of 0 to 255.
Files are composed of individual bytes. So, each byte represents a value between 0 and 255, which can be seen as an integer. For example, the byte 0xA5 corresponds to binary value 10100101 or the integer 165. When reading data from a file, we retrieve the bytes, which are then treated as integers.
Unbuffered Approach
In the FileCopyNoBuffer method, I demonstrate an unbuffered approach to file copying, which basically works by reading data byte-by-byte using a FileInputStream and writing each byte directly to the output file using a FileOutputStream.
During the file copying process, we read each byte as an integer using the read() method of FileInputStream. This method returns an integer representing the next byte from the input file, ranging from 0 to 255 which we then convert back to a byte before being written to the output file.
Note: What REALLY happens in a low-level overview, for those interested, is that since bytes in Java are represented as signed integers, we need to ensure that only the least significant 8 bits of the integer value are retained. And for this, we use an approach known as "truncation". Truncation discards the upper bits of the integer value, leaving only the least significant 8 bits intact. These 8 bits represent the actual byte value we want to write to the output file. Finally, after the truncation step, we convert the truncated integer value back to a byte using the appropriate casting or conversion operation.
Buffered Approach
The FileCopyWithBufferAndArray method demonstrates a buffered approach to file copying. Specifically we use BufferedInputStream and BufferedOutputStream.
First of all, a buffer of a fixed array, 4096 bytes (4KB) in our case, is allocated to hold the data. The buffer acts as an intermediate storage, allowing for efficient data transfer between the input and output streams. Reading and writing larger chunks of data at once rather than byte-by-byte. This minimizes the overhead of frequent I/O operations, and of course improves the performance. Finally, the BufferedOutputStream writes the data from the buffer to the output file.
Microbenchmark
public class IODemo {
static String inputFile = "takis.txt";
static String outputFile = "output.txt";
public static void fileCopyNoBuffer() {
System.out.println("\nRunning fileCopyNoBuffer ...");
long startTime, elapsedTime;
try (FileInputStream in = new FileInputStream(inputFile);
FileOutputStream out = new FileOutputStream(outputFile)) {
startTime = System.nanoTime();
int byteRead;
while ((byteRead = in.read()) != -1) {
out.write(byteRead);
}
elapsedTime = System.nanoTime() - startTime;
System.out.println("Elapsed Time: " + (elapsedTime / 1000000.0) + " ms");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void fileCopyWithBufferAndArray() {
System.out.println("\nRunning fileCopyWithBufferAndArray ...");
long startTime, elapsedTime;
startTime = System.nanoTime();
try (BufferedInputStream in = new BufferedInputStream(new FileInputStream(inputFile));
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(outputFile))) {
byte[] byteBuf = new byte[4096];
int numBytesRead;
while ((numBytesRead = in.read(byteBuf)) != -1) {
out.write(byteBuf, 0, numBytesRead);
}
elapsedTime = System.nanoTime() - startTime;
System.out.println("Elapsed Time: " + (elapsedTime / 1000000.0) + " ms");
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
File fileIn = new File(inputFile);
System.out.println("File size: " + fileIn.length() + " bytes");
fileCopyNoBuffer();
System.out.println();
fileCopyWithBufferAndArray();
}
}
Performance Comparison
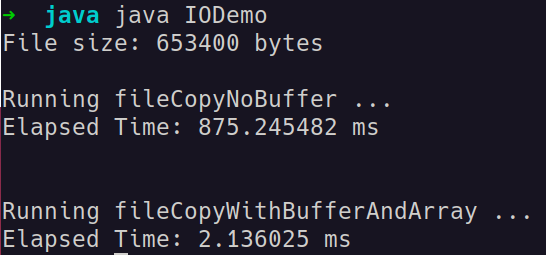
In this microbenchmark, we can see a significant performance difference between the two approaches. The buffered approach outperformed the unbuffered approach, demonstrating much faster execution times.
Disclaimer
It's worth mentioning that there are scenarios where reading byte-by-byte may be the most appropriate solution. For instance, when dealing with extremely large files or situations where memory constraints are a concern, reading data in smaller chunks can be a better approach. It allows for better memory management and reduces the risk of overwhelming the available resources. In such cases, by reading and writing data byte-by-byte, engineers have more control over the memory usage.